Apache Hadoop
BIG Data — Apache Pig Latin
In recent years, utilizing big data has become an inseparable part of software development. Many companies store their customers’ data and use it to improve their service.
Apache Hadoop is one of the essential software that manages data processing and storage for big data applications. Apache Pig Latin is a high-level language for expressing data analysis programs and a related project of Apache Hadoop.
Apache Pig Latin is a language that is executed over Apache Hadoop. Apache Hadoop is designed to solve the problem of scaling up databases with distributed processing. Also, it was a very innovative software that was expected to be an alternative database from the SQL database for a while. As one proof, Hadoop developers believed that there are various use case opportunities such as financial services, health care, manufacturing. Likewise, they thought that Apache Hadoop would process more than half the world’s data by 2015.
Who’s using Hadoop?
Many tech companies such as Uber, Airbnb, Netflix, Spotify, Slack, etc., have used Hadoop to process extensive data.
For example, Uber has started to use Apache Hadoop in 2015. Before using Apache Hadoop, they had stored a limited amount of data into multiple SQL databases. Yet this architecture is not so bad when they had only 100GB to a few Terabytes of data. However, with Uber’s business growing exponentially, the amount of incoming data also increased, and they need to access all data from one place to analyze all the data. Besides, they mentioned scaling their data server became increasingly expensive. After introducing Apache Hadoop, they could build the architect to keep the platform scalable and store over a petabyte of data. Also, they resolved their financial problems.
Furthermore, Netflix had been using Apache Hadoop since 2013, a little earlier than Uber, and their Hadoop-based data warehouse was petabyte-scale.
History
Apache Pig Latin is one of the Apache Hadoop-related projects proposed and initially developed by engineers of Yahoo! research to make it simple to implement map-reduce on parallel database products. Later, engineers who work for tech companies such as Google, LinkedIn, IBM, Cloudera, etc., have maintained Apache Pig Latin. The developers released the first version of 0.1.0 on 11 September 2008. After that, version 0.1.1 was released on 5 December 2008 as the first release as a Hadoop subproject. The latest version, 0.17.0, was released on 19 June 2017; thus, there is no release since about four years ago because almost all proposed implementation is completed. Therefore, we can use Apache Pig Latin without being afraid of disruptive change for language specifications. In other words, there is no longer a need to evolve as the needs of developers have decreased.
Benefits and Downsides
There are several advantages to using Apache Pig Latin, but the most significant benefit is its ease of writing. When developers directly write map-reduce programs for Hadoop, they need to write complex map-reduce programs using Java or Python. In contrast, with Apache Pig Latin, developers do not need to write complex programs and reuse them for other purposes. Let’s look at the practice of Netflix. They describe in their article that they use Apache Pig Latin for production cluster for ETL (extract, transform, load) jobs and algorithms. Also, they mention they use vanilla Java-based map-reduce for some complex algorithms. We can learn from this practice that Apache Pig Latin can fit for practical use, not just ad hoc usage or pseudo-codes. However, Apache Pig Latin may not be suitable for complex algorithms.
Disadvantages
Instead of having some advantages, Apache Pig Latin has two major downsides:
- Ease of writing could be a disadvantage depending on circumstances. In Apache Pig Latin, Data Schema is not enforced explicitly, and this could be the cause of making a bug in a program. This characteristic is why some developers sometimes avoid using Apache Pig Latin and prefer to use Vanilla Java-based or Python-based map-reduce even though it is not easy to write.
- It is not easier to learn Apache Pig Latin than SQL, even if that is easier than Java-based or Python-based map-reduce. At that time, a pure SQL database was expensive to store big data, but many developers could instead use SQL if there were no financial reasons.
Trends
Apache Pig Latin is used a lot with Apache Hadoop in the 2010s. As of now, it has got 622 GitHub stars along with 448 GitHub forks.
So why has the development of Apache Pig Latin stopped? One reason is that one of the systems of Apache Hadoop has a scalability problem. The name of that system is HDFS: The Hadoop Distributed File System. Uber mentioned that the problem in their article as the limitation usually occurs when data size expands over ten petabytes and becomes a real issue over 50–100 petabytes. Similarly, Netflix described Apache Hadoop as software for managing and processing hundreds of terabytes to petabytes of data. As mentioned in the History chapter, Uber was storing less than a petabyte of data when using Apache Hadoop. Afterward, as their services expanded, the amount of data grew, and it is easy to imagine that they would have faced the limitation problem.
With that background, other technologies have been about to replace Apache Pig Latin and Apache Hadoop. Those technologies are Apache Spark and cloud storage services. Apache Spark is designed to solve the problem of Apache Hadoop. In short, it is much faster, and its language is more simple than Apache Hadoop. As a result, many companies that used Apache Hadoop use Apache Spark as well. Uber and Netflix are among them.
Cloud storage services such as AWS, Google Cloud Platform, Microsoft Azure have released a new service that allows customers to build big and super-fast SQL databases at a low price. For example, Google BigQuery is an enterprise data storage service that developers can operate with SQL queries. Storing and querying big data can be time-consuming and expensive without the right hardware and infrastructure, but this product solves that problem using Google’s infrastructure’s processing power. This product is a mainstream GCP service, and they recommend migrating Apache Hadoop or Spark system to GCP’s database service.
Incidentally, Netflix has used Amazon Web Services instead of HDFS since the beginning, which is why they could store petabyte-scale data on their data warehouse. We can learn from this practice that it is essential to understand tools and sometimes consider other ways that are different from conventional methods.
Sample codes
In this section, I will provide some sample codes about the if statement and the loop.
If statement
Unlike other programming languages, there is no if statement in Apache Pig Latin. Alternatively, programmers can express conditional branches like the if statement with case operator and bincond operator. The case operator works as a switch statement or like an if statement. Also, the bincond operator works like a combination of the if statement and else statement. This type of operator is called “conditional operator” or “ternary operator” in other popular high-level languages such as Java, JavaScript, and C++.
Case operator
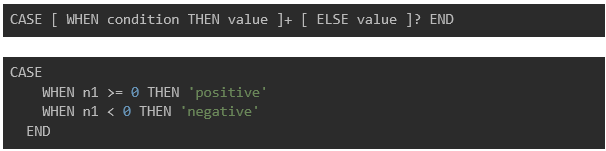
There are two ways to write a CASE statement, and we can use them in different situations.
#1: Writing like the if-else statement
#2 Writing like the switch statement
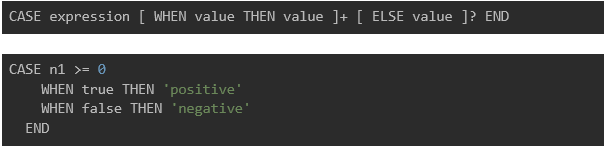
It is desirable to use #1 when using multiple branching conditions, but #2 is more suitable when needing outputs from a single condition.
Bincond operator
The bincond operator works as below. Note that the bincond should be enclosed in parenthesis.

Nested bincond operators are equivalent to Case operators. While the conditional operator (bincond operator) has the advantage of being able to write a conditional branch in a single line, there are two downsides. First, some programmers think it is an oversimplified expression because of the lack of readability and clearness of code.
As we can see, the bincond operator is composed of only two symbols: “?” and “:”, thus there is the opinion that the conditional operator is hard to find. Likewise, it is hard to read if the condition and values in bincond are too long. Hence, programmers prefer to keep a single line when using bincond.
The conditional operator is not appropriate when expressing a single condition. It is possible to write the expression for either one condition and leave another one empty, but the if statement is more suitable in that case. Thus if we want to write only the expression for when the condition is True, we should also write the expression when the condition is False.
Loop
FOREACH is the relational operator to express a loop statement in Apache Pig Latin. This relational operator generates new data based on given data. Apache Pig Latin doesn’t have loop statements such as for loop and while loop in python.

This program will copy all column data to X without breaking the structure of A.
Takeaway
Apache Pig Latin is an instrumental language. The proof is that many tech companies use it for not only algorithms in production but analysis. Apache Pig Latin is much more straightforward than vanilla python-based or Java-based MapReduce. However, Apache Pig Latin’s platform: Apache Hadoop, has been replaced by other technologies such as Apache Spark and cloud storage services. Even though Apache Hadoop was evaluated as an innovative technology when it appeared, many of the major languages in use today were produced before the 2000s and will continue to adapt or be replaced with better competitors.
